
DDL, DML, DCL
- DDL(정의어)
- 데이터베이스 구조를 정의, 수정, 삭제하는 언어
- Alter, Create, Drop
- DML(조작어)
- 데이터베이스내의 자료 검색, 삽입, 갱신, 삭제를 위한 언어
- Select, Insert, Update, Delete
- DCL(제어어)
- 데이터에 대해 무결성 유지, 병행 수행 제어, 보호와 관리를 위한 언어
- Commit, Rollback, Grant, Revoke
트랜잭션
- 데이터베이스에서 하나의 논리적 기능을 수행하기 위한 작업의 단위
- 여러 쿼리를 묶는 단위
- 커밋(commit): 트랜잭션의 쿼리가 성공적으로 처리되었다고 확정하는 명령어
- 롤백(rollback): 트랜잭션으로 처리한 과정을 일어나기 전으로 되돌리는 일
특징(ACID)
- 원자성(atomicity): 트랜잭션과 관련한 일이 모두 수행되었거나 모두 수행되지 않았거나를 보장하는 특징
- 일관성(consistency): 허용된 방식으로만 데이터를 변경해야 하는 것
- 격리성(isolation): 트랜잭션 수행 시 서로 끼어들지 못하는 것, 서로 격리되어 마치 순차적으로 실행되는 것처럼 작동
- 지속성(durability): 성공적으로 수행된 트랜잭션은 영원히 반영되어야 하는 것
- 처크썸: 중복 검사로 오류 정정
- 저널링: 파일/데이터베이스 시스템의 변경 사항을 반영하기 전에 로깅하는 것
- 무결성: 데이터의 정확성, 일관성, 유효성을 유지하는 것
트랜잭션의 격리성
- 트랜잭션이 순차적으로 실행되면 격리성은 높아지지만 동시성은 낮아져 성능이 떨어짐 (격리성과 동시성은 반비례)
- 트랜잭션이 동시에 실행되면 동시성은 높아지지만 격리성이 낮아지고 서로간의 간섭이 발생할 수 있음
트랜잭션의 격리 수준
- serializable: 커밋 완료된 데이터에 대해서만 조회할 수 있으며 트랜잭션을 순차적으로 진행시키는 것
- repeatable_read: 커밋 완료된 데이터에 대해서만 조회할 수 있으며 하나의 트랜잭션이 수정한 행을 다른 트랜잭션이 수정할 수 없도록 막아주지만 새로운 행을 추가하는 것은 막지 않음
- 반복해서 행을 조회하더라도 똑같은 행을 보장하지만 똑같은 범위의 쿼리를 실행했을 때는 이후에 추가된 행이 발견될 수 있음(팬텀리드)
- read_commited: 커밋 완료된 데이터에 대해서만 조회할 수 있으며 커밋이 되지 않은 정보는 읽지 못함
- read_uncommited: 가장 낮은 격리 수준, 다른 트랜잭션이 커밋하지 않은 정보를 읽을 수 있음
트랜잭션의 격리 수준에 따른 현상
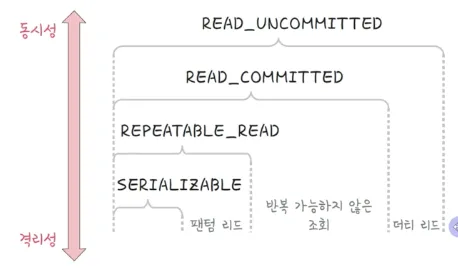
- 팬텀리드: 한 트랜잭션 내에서 동일한 쿼리를 2번 이상 보냈을 때 해당 조회 결과가 다름 (테이블이 다름)
- 반복 가능하지 않은 조회: 한 트랜잭션 내의 같은 행에 두 번 이상 조회가 발생했는데 그 값이 다른 것 (행/로우가 다름)
- 더티리드: 하나의 트랜잭션이 다른 트랜잭션의 아직 커밋되지 않은 데이터를 읽는 현상 (롤백을 했어도)
RDBMS VS NoSQL
- 관계형 데이터베이스(RDBMS)
- 행과 열을 가지는 테이블 형식의 데이터를 저장, 관계를 명시
- SQL 사용
- 관계를 통해 데이터를 중복없이 한번만 저장 가능하지만 스키마 변경이 어려움
- 데이터 구조가 명확하며 변경 여지가 없을 때, 데이터가 자주 변경되는 경우 사용
- NoSQL 데이터베이스
- 유연한 스키마, key-value 등 다양한 형식으로 데이터를 저장 → 확장성
- SQL 사용 X
- 스키마가 없어 유연하고 데이터를 읽는 속도가 빠르지만 데이터 중복이 발생할 수 있음
- 데이터를 자주 읽지만 변경이 자주 없는 경우, 많은 양의 데이터를 다루어야 하는 경우 사용
특징 비교
- RDB는 관계형으로 정해진 형식에 따라 테이블에 데이터를 저장하지만 NoSQL은 다양한 방식으로 데이터 저장
- RDB는 스키마가 정적(고정적)이지만, NoSQL은 유연한 스키마 구조를 갖는다.
- RDB는 수직 확장이 용이하고, NoSQL은 수평 확장도 용이하다. (즉, RDB는 서버 용량을 늘리는 게 쉽고, NoSQL은 서버를 여러 대 늘리는 게 쉽다)
- RDB는 복잡한 쿼리와 Join 연산이 가능하다. NoSQL은 구조화된 쿼리 언어가 없는 경우도 많고, 일반적으로 Join이 없다.
- RDB는 OLTP에 적합하고, NoSQL은 OLAP에 적합하다. (즉, RDB는 트랜잭션 처리에 용이하고, NoSQL은 분석 처리에 용이하다)
Redis
redis는 인메모리 키-값 모델이다. 말그대로 인-메모리이기 때문에 데이터 접근 & 대기시간이 매우 매우 짧다. 따라서 주로 데이터 캐시, 메시지 브로커 & 대기열로 쓰임
- 동시에 대량의 트래픽을 처리하는 웹서비스에서 데이터를 캐시하는 중간 DB 역할로 많이 씀 (1만명이 MySQL 칠 트래픽을 redis가 값을 가져와서 막아준다고 생각하면 됨)
- celery, airflow 등의 분산 처리 프레임워크에서 메시지 브로커로 많이 쓴다. (‘분산’ 처리이기 때문에 워커나 태스크 사이의 데이터를 주고받을 때 중개자가 필요함. 그 역할을 수행한다)
인덱스
- 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조
- 데이터를 빠르게 찾을 수 있는 수단으로, 테이블의 조회 속도를 높여주는 자료구조 (테이블의 특정 레코드의 위치 알려주는 용도)
B+Tree 인덱스

- B-Tree의 변형으로 B-Tree는 특정 데이터 검색은 효율적이지만 데이터 순회 시 모든 노드를 방문해야 한다는 단점 개선
- 리프 노드에만 데이터를 저장, 다른 노드에서는 자식 노드를 가리키는 포인터만 저장
- 리프 노드끼리는 연결리스트(Linked List)로 연결
- 리프 노드를 제외하고는 데이터를 저장하지 않기 때문에 메모리를 더 확보하여 더 많은 포인터를 담을 수 있어 검색 속도 향상
- 풀 스캔을 하는 경우 연결리스트로 연결되어 있는 리프 노드만 순회하면 되기 때문에 효율적
- 인덱스의 경우 부등호를 이용한 순차 검색 연산이 자주 발생하므로 B+Tree를 주로 사용
해시 테이블
- key와 value를 한 쌍으로 데이터를 저장하는 자료구조
- 해시 함수는 값이 조금이라도 달라지면 완전히 다른 해시 값을 생성해 등호(=) 연산을 이용한 검색에 최적화 되어 있음
- 부등호(<, >) 연산이 자주 사용되는 검색을 위해서는 적합하지 않음
정규화/반정규화
-
- 1차 정규화: 테이블의 컬럼이 하나의 값을 갖도록 테이블을 분리시키는 것
- 2차 정규화: 제1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해하는 것
- 3차 정규화: 제2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해하는 것
- 데이터 구조의 변경을 최소화할 수 있고 데이터의 정확성이 높지만 정규화 수준이 높으면 조회 시 많은 조인이 발생함정규화: 하나의 릴레이션에 하나의 의미만 존재할 수 있도록 릴레이션을 분해해 나가는 과정

- 반정규화: 조인을 줄여 조회 성능을 높이고자 데이터 중복을 허용하는 것
- 조인이 줄어 검색 속도가 향상하지만 중복 데이터로 인해 수정/삭제 성능은 낮아짐
ORM
- 객체지향 프로그래밍에서의 객체와 관계형 데이터베이스의 테이블 사이의 불일치를 해결
- 객체 간의 관계를 바탕으로 SQL을 자동으로 생성하여 불일치를 해결
장점
- 객체지향적인 코드로 인해 더 직관적이고 로직에 집중할 수 있음
- 객체를 활용하기 때문에 재사용 및 유지보수의 편리성 증가함
- DBMS에 대한 종속성이 줄어듬 → DBMS가 교체되더라도 부담이 적음
단점
- ORM 만으로 완벽히 서비스를 구현하기 어려움 → 데이터 구조의 복잡성이 클 경우
- 조인이 많거나 프로시저가 많은 시스템에서는 활용하기 어려움 → 프로시저를 다시 객체로 바꿀 경우 생산성 저하나 리스크가 발생 가능
Key
- 슈퍼키
- 유일성 만족, 최소성 만족 X
- 후보키
- 유일성 만족, 최소성 만족
- 기본키
- 후보키 중 NULL값을 가질 수 없고 같이 변경될 수 없으며 단순한 키 선택
- 대체키
- 후보키 - 기본키
- 외래키
- 다른 릴레이션의 기본키를 잠조하는 키
- 릴레이션간의 관계를 나타냄
트리거
- 특정 테이블에 대한 이벤트에 반응해 INSERT, DELETE, UPDATE 같은 DML 문이 수행되었을 때, 데이터베이스에서 자동으로 동작하도록 작성된 프로그램
- 사용자가 직접 호출하는 것이 아닌, 데이터베이스에서 자동적으로 호출
DELETE, TRUNCATE, DROP
- DELETE
- Where절로 테이블 내 데이터를 선택하여 원하는 데이터만 제거
- 테이블 용량은 줄어들지 않음
- 트랜잭션 내에서 ROLLBACK으로 삭제한 데이터 되돌릴 수 있음
- TRUNCATE
- 전체 데이터 사제
- 테이블 용량이 줄어들고 인덱스 등도 삭제되지만 테이블은 자체는 그대로 있음
- 자동 COMMIT되어 삭제한 데이터 되돌릴 수 없음
- DROP
- 테이블 자체를 삭제
- 테이블 저장 공간, 인덱스, 객체 모두 삭제
- 자동 COMMIT되어 삭제한 테이블/데이터 되돌릴 수 없음
https://www.tistory.com/event/write-challenge-2024
작심삼주 오블완 챌린지
오늘 블로그 완료! 21일 동안 매일 블로그에 글 쓰고 글력을 키워보세요.
www.tistory.com
'🎈 > 면접 준비' 카테고리의 다른 글
| [Oracle] 계층형 쿼리 (0) | 2024.11.12 |
|---|---|
| [기술 면접] 자료구조, 알고리즘 (0) | 2024.11.10 |
| [기술 면접] 네트워크 (2) | 2024.11.07 |
| [CS 지식] CI/CD에 대해서 (8) | 2024.11.06 |
| [기술 면접] 운영체제 (5) | 2024.11.06 |